
W dzisiejszym świecie innowacji, duże modele językowe (#LLMs – Large Language Models) wyróżniają się jako jedne z najbardziej przełomowych narzędzi w dziedzinie sztucznej inteligencji. Z ich zdolnością do tworzenia tekstu, generowania treści i analizy danych przychodzi jednak pytanie – jak korzystać z tych modeli w jak najbardziej efektywny sposób?
Ten artykuł zawiera zbiór praktycznych porad, które pomogą wam odnaleźć się w dziedzinie dużych modeli językowych. Niezależnie od tego, czy jesteście początkującymi entuzjastami, czy macie już doświadczenie w pracy z tymi narzędziami, znajdziecie tu cenne wskazówki, które pozwolą wam przekuć teorię w praktykę.
Jaki model wybrać?
Modele językowe rozwijają się obecnie w takim tempie, że ich ilość z tygodnia na tydzień stale rośnie. Co za tym idzie, czasami można pogubić się przy wyborze modelu, który odpowiadałby naszym potrzebom.
Jeśli zaczynacie swoją przygodę z wykorzystaniem modeli językowych, chcecie je przetestować albo potrzebujecie czegoś, co jest od razu gotowe do użycia, najlepiej wtedy użyć modeli, które są popularne i powszechnie dostępne. Przykłady chatbotów bazujących na takich modelach to #ChatGPT i ChatGPT Plus (płatna wersja), #Bard lub #Claude. Jeśli chcecie się dowiedzieć czegoś więcej o propozycjach od OpenAI i Google, polecamy nasz artykuł porównujący ChatGPT i Barda.
Natomiast jeśli potrzebujecie bardziej specjalistycznych modeli, polecamy używać rozwiązań typu open source. Na przykład, jeśli zależy wam na tym, aby model pomagał wam w programowaniu, warto skorzystać z jednego z wariantów modeli takich jak #StarCoder, #CodeLlama czy #WizardCoder. Modele typu open source są również dobrym wyborem, jeśli ktoś jest zainteresowany uruchomieniem modelu lokalnie, np. w celu ochrony wrażliwych danych. Większość otwartych modeli (nie tylko językowych) można znaleźć i skorzystać z ich wersji demonstracyjnych na platformie HuggingFace. Szczególnie wartymi uwagi są modele z serii Llama 2 i ich pochodne (poddane procesowi fine-tuningu).
Warto eksperymentować
Jeśli zaczęliście już korzystać z modeli językowych, ale wyniki was nie zadowalają, warto eksperymentować z promptami, czyli instrukcjami dla modeli. Dobre sformułowanie promptu może pomóc uzyskać lepsze i bardziej precyzyjne odpowiedzi. Proces tworzenia i ulepszania promptów określa się jako prompt engineering. Ten proces może obejmować formułowanie zapytania, określanie stylu odpowiedzi, dostarczanie kontekstu lub przypisywanie roli AI. Im więcej informacji podamy modelowi dotyczących tego, czego oczekujemy, tym lepiej jego odpowiedź będzie spełniać nasze oczekiwania.
Czasami wystarczy użyć jakiegoś zwrotu, żeby uzyskać lepszy i bardziej oczekiwany wynik. Poniżej podajemy kilka przykładów:
- – Wciel się w rolę eksperta bankowości
- – Zachowuj się jak native speaker francuski
- – Podaj jak najwięcej przykładów dotyczących…
- – Dopracuj swoją odpowiedź
Warto też dostarczyć modelowi jak najwięcej informacji kontekstowych, wtedy jego odpowiedź będzie bardziej precyzyjna. Przykładowo, zamiast “Napisz tekst o organizacji czasu” można napisać “Napisz tekst na bloga biznesowego o tym, jak ważna jest organizacja czasu w małej firmie”.
Należy też pamiętać, aby podać modelowi informacje niezbędne do tego, żeby jego odpowiedź była prawidłowa. Na przykład, jeśli użytkownik chce uzyskać podsumowanie jakiegoś artykułu w kilku punktach, powinien podać modelowi treść tego tekstu.
Kolejną istotną informacją dla modelu jest to, jak długa ma być jego odpowiedź i w jakim ma być formacie. Można poprosić model, żeby przygotował tekst zawierający np. daną ilość znaków w formacie CSV.
Ciekawą praktyką jest też poproszenie samego modelu o to, żeby pomógł w przygotowaniu promptu. Użytkownik może w takim przypadku napisać jakąś ogólną instrukcję, a model może w odpowiedzi podać bardziej szczegółową wersję. Poniżej znajduje się przykład:
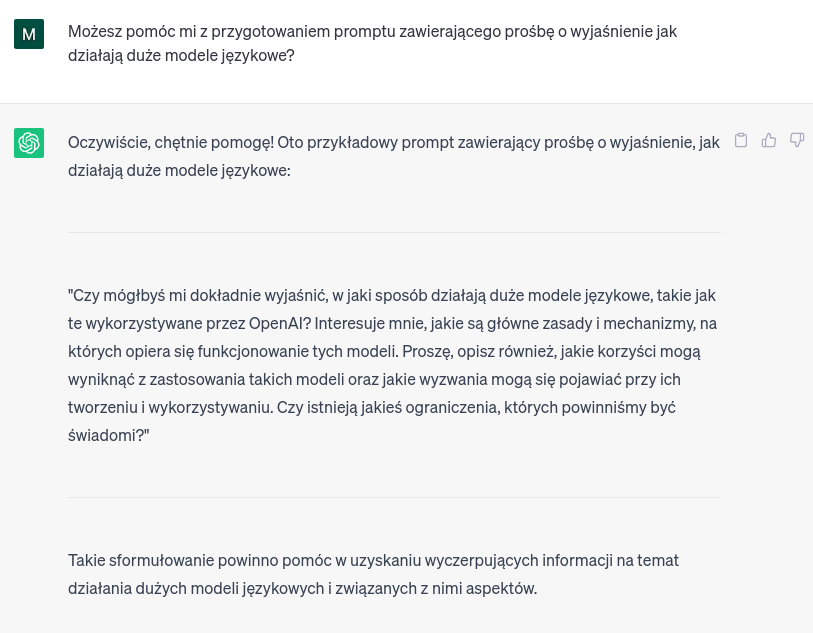
Jak widać, istnieje wiele sposobów (nie tylko podanych w naszym artykule jako przykłady, użytkownicy nie mają w zasadzie żadnych ograniczeń oprócz ilości wprowadzanych tokenów) na to, aby urozmaicić prompt i osiągnąć dzięki temu lepszy wynik. Polecamy też szukać inspiracji wśród innych użytkowników. Bardzo ciekawą strategią na pracę z modelem językowym przedstawiono w tym filmie na TikToku – autor używa jednego zdania, które zachęca ChatGPT do zadawania mu pytań przed stworzeniem ostatecznej treści, żeby lepiej zrozumieć oczekiwania użytkownika.
Co zrobić, jeśli chcemy douczyć model swoimi własnymi danymi?
W takim przypadku, jak już wspomnieliśmy, warto użyć modelu typu open source. Istnieje kilka metod douczania, należy więc wybrać taką, jaka najlepiej spełnia wasze oczekiwania.
Pierwszą opcją jest wspomniany już prompt engineering, #ICL – In Context Learning oraz #CoT – Chain of Thought.
Jeśli chodzi o ICL, ta metoda pozwala modelom językowym uczyć się zadań podanych tylko w kilku przykładach w formie demonstracji. W przypadku ICL należy pokazać modelowi kilka próbek, które zobrazują mu, jak wykonać zadanie. Na przykład, jeśli chcemy, aby model językowy nauczył się określać tematy zdań lub wypowiedzi, można mu podać prompt podobny do poniższego:
Podaj tematy ostatnich dwóch zdań, tak jak jest to zrobione w przykładach poniżej:
"Zdanie" -> "Temat"
"Zamówmy sobie pizzę z podwójnym serem." -> "Jedzenie"
"Jutro ma padać deszcz." -> "Pogoda"
"Przygotowuję się do egzaminu z historii" -> Edukacja
"Zamierzam zacząć prowadzić własną firmę" -> Przedsiębiorczość
"Antybiotyki nie działają na wirusy." -> ?
"Real Madryt wygrał mecz." -> ?
Po zapoznaniu się z tymi przykładami model językowy będzie mógł klasyfikować wypowiedzi w nowych sytuacjach, których nie widział wcześniej. Strategia douczania przedstawiona w powyższym przykładzie nazywa się few-shot learning (model dostaje kilka przykładów); innymi wariantami są one-shot learning (model dostaje jeden przykład) i zero-shot learning (model nie dostaje przykładu, tylko od razu proszony jest o klasyfikację). Te strategie podawania kilku, jednego lub żadnego przykładu można zastosować też w innych przypadkach douczania, np. w niżej opisanej metodzie CoT.
CoT, czyli Chain of Thought, to metoda podawania promptów w taki sposób, aby model wyjaśniał, dlaczego podaje akurat taką, a nie inną odpowiedź – tłumacząc dosłownie, żeby zaprezentował swój łańcuch myśli. Stosowanie tej metody pozwala na uzyskanie bardziej dokładnych wyników.
Przykładowo, możemy użyć one-shot learning, żeby pokazać modelowi, że oczekujemy, żeby wytłumaczył, jak doszedł do poprawnej odpowiedzi. Poniżej znajduje się przykładowy prompt:
Pytanie: Marcin miał 3 piłki. Kupił jeszcze 2 opakowania piłek, a każde opakowanie zawiera po 2 sztuki. Ile piłek ma aktualnie Marcin?
Odpowiedź: Na początku Marcin miał 3 piłki. Jeśli kupił 2 opakowania piłek i w każdym z nich były 2 piłki, to razem dokupił 4 piłki. 3 + 2 * 2 = 7. Odpowiedź: Marcin ma aktualnie 7 piłek.
Pytanie: Rano w piekarnii pracownicy mieli dostępnych 100 kilogramów mąki. Zużyli 73 kilogramy i następnie dokupili 50 kilogramów. Ile kilogramów mąki jest teraz w piekarni?
Po podaniu powyższego przykładu oczekujemy, że odpowiedź modelu nie będzie brzmiała po prostu “77 kilogramów”, lecz że zostanie przedstawione wytłumaczenie, jak model doszedł do takiego wniosku:
Odpowiedź: Jeśli ze 100 kilogramów mąki pracownicy piekarni zużyli 73 kilogramy, to zostało im 27 kilogramów. Następnie kupili jeszcze 50 kilogramów, więc 27 kilogramów + 50 kilogramów = 77 kilogramów. Odpowiedź: W piekarni dostępnych jest obecnie 77 kilogramów mąki.
Prompt engineering, ICL i CoT sprawdzą się w sytuacjach, w których nie mamy ogromnej ilości danych do douczenia. Te metody są najszybsze i najtańsze, lecz z drugiej strony także najbardziej ograniczone wśród metod douczania, mimo tego, że mają duże możliwości – prompty podawane modelom mają limity wprowadzanych tokenów.
Kolejną metodą douczania jest fine-tuning – proces, w którym bazowy model językowy jest dostosowywany do konkretnego zadania lub zestawu danych. W wyniku tego procesu otrzymujemy nowy model. Ta metoda wymaga więcej pracy, funduszy i poziomu zaawansowania niż prompt engineering i ICL lub CoT, jednak efekty fine-tuningu mogą być lepsze. Fine-tuning lepiej sprawdzi się, jeżeli jest dużo danych do douczenia.
Oprócz zastosowania powyższych metod można też przeprowadzić pełny trening modelu, czyli nauczyć model wszystkiego od podstaw. Do tego potrzeba ogromnej ilości danych, pracy i ten proces jest bardzo kosztowny ze względu na to, że potrzebna jest duża moc obliczeniowa. Ta metoda jednak ma największe możliwości – w tym przypadku nie ma żadnego limitu, można stworzyć tak duży model, jak tylko się potrzebuje.
Zalety używania frameworków
Warto również korzystać z frameworków do pracy z modelami. Znacznie przyspieszają one proces rozwoju, testowania i wdrożenia. Są to zestawy narzędzi i bibliotek programistycznych, które umożliwiają łatwe tworzenie, trenowanie i wykorzystywanie zaawansowanych modeli językowych. Te frameworki dostarczają gotowe rozwiązania implementacyjne, obliczeniowe oraz narzędzia do eksperymentowania z różnymi modelami. Zakres ich zastosowań jest naprawdę szeroki – można ich używać do podłączania różnych źródeł danych do modelu, do obsługi ruchu i obciążenia, do stworzenia wyszukiwarki semantycznej, indeksacji danych czy do stworzenia interfejsu do obsługi modeli. Przykłady popularnych frameworków to #LlamaIndex, #LangChain czy #Gradio (do tworzenia interfejsu użytkownika). Ilość dostępnych frameworków i ich funkcjonalności ciągle rośnie i naprawdę warto z ich pomocą ułatwić sobie pracę.
Ograniczenia dużych modeli językowych
Bardzo ważna jest świadomość tego, jakie ograniczenia i zagrożenia niosą za sobą duże modele językowe. Są to potężne narzędzia, jednak należy pamiętać, że nie są pozbawione wad. Przede wszystkim, używając publicznych modeli językowych należy uważać na swoje dane – to, co podajemy modelom, często jest używane do ich trenowania, a w efekcie inny użytkownik może przypadkowo dostać wasze dane w odpowiedzi na jego prompt. Należy zatem pamiętać, aby nie podawać publicznym modelom danych wrażliwych.
Kolejną ważną sprawą, o której należy pamiętać jest fakt, że duże modele mają tendencje do halucynowania, czyli podawania fałszywych informacji. Dlatego nie należy wszystkich informacji podawanych przez model przyjmować za pewnik, tylko trzeba je weryfikować.
Jeśli chcecie dowiedzieć się więcej o zagrożeniach związanych z używaniem dużych modeli językowych, to zachęcamy was do przeczytania naszego artykułu na ten temat.
Bonus dla zaawansowanych
Jak już wspomnieliśmy, jedną z metod douczania modeli jest CoT, czyli Chain of Thought, której podstawą jest to, że model uzasadnia swoją odpowiedź. Ta idea została rozszerzona do procesów rozumowania o strukturze grafu – “Graph of Thought”. Istnieją już 2 wersje takiego rozwiązania opisane przez dr. Camerona R. Wolfe’a.
Główna różnica między Chain of Thought a Graph of Thought jest taka, że w przypadku pierwszej metody wyjaśnienie modelu ma strukturę liniową (model wyjaśnia krok po kroku, jak doszedł do jakiegoś wniosku), a w przypadku Graph of Thought wyjaśnienie jest bardziej złożone i lepiej odwzorowuje sposób, w jaki myślą ludzie – nasze myśli często się ze sobą łączą, czasami przeskakujemy między jedną a drugą; nie myślimy cały czas w sposób liniowy, lecz jest to bardziej skomplikowany proces.
Pierwsza wersja takiego rozwiązania, #GOTR (Graph of Thought Reasoning), jest techniką dwuetapową. Pierwszy krok to opracowanie wyjaśnienia podanego zagadnienia lub problemu na podstawie tekstu i obrazu podanego w prompcie. Drugi krok to podanie przez model ostatecznej odpowiedzi, która jest powiązana z wcześniej opracowanym wyjaśnieniem. Architektura tego podejścia jest oparta na enkoderze i dekoderze, a model poddany jest odpowiedniemu procesowi fine-tuningu. Kilka enkoderów pobiera dane i wyniki ich przetwarzania są łączone. Model generuje graf jednostek nazwanych (named entity graph) na podstawie tekstu wejściowego i wygenerowanego uzasadnienia. Następnie ten graf jest przetwarzany przez enkoder z wykorzystaniem sieci atencji i łączony z wszystkimi cechami obrazów/tekstu. W ten sposób dekoder otrzymuje informacje z treści, obrazu i danych wejściowych opartych na grafie.
Druga wersja, #GoT prompting, korzysta z systemu składającego się z przyczynowych modeli językowych i promptów do tworzenia uzasadnień zgodnie ze strukturą grafu. W tym przypadku grafy są zbudowane tak, że każdy z węzłów przedstawia jakąś myśl, a połączenia wskazują na to, że dana myśl została wygenerowana na podstawie innej myśli. Wspomniane przyczynowe modele językowe składają się z kilku modułów monitorujących proces tworzenia uzasadnień. Top-level controller nadzoruje proces powstawania uzasadnień, parser weryfikuje i wydobywa odpowiedź modelu językowego, scorer ocenia jakość rozwiązań, a prompter tworzy prompty dla wszystkich modułów. Taki system jest wykorzystywany do przetworzenia struktury grafu na odpowiedź podawaną użytkownikowi.
Uważa się, że te 2 podejścia zdecydowanie bardziej przypominają proces myślowy człowieka niż CoT i mogą być bardzo pomocne w przypadkach, gdy użytkownik potrzebuje takiego rozwiązania. Jednak te techniki są droższe i pomocne tylko w niektórych sytuacjach.
Bądź na bieżąco i nie wahaj się prosić o pomoc
Już nie raz w naszych artykułach wspominaliśmy i ciągle to podkreślamy, że dziedzina dużych modeli językowych rozwija się niezwykle dynamicznie. Nowe modele i narzędzia do pracy z nimi są tworzone niezwykle szybko, dlatego warto być na bieżąco z newsami w świecie #AI.
Warto też prosić o pomoc, jeśli tego potrzebujecie. Może macie potrzebę stworzenia własnego modelu językowego albo potrzebujecie pomocy z wykorzystaniem już istniejącego? Nasz zespół w Azurro chętnie wam w tym pomoże, więc zapraszamy do kontaktu 🙂

Post a Comment