
Polska od dłuższego czasu czekała na lokalny model językowy, który będzie w stanie wspierać naszą społeczność w celach prywatnych, naukowych, administracyjnych, biznesowych i wielu innych. W ostatnim czasie opublikowano Bielika – obecnie najlepszy (według tego leaderboardu) polski duży model językowy (dostępny w dwóch opcjach – bazowej i instruct), powstały dzięki współpracy SpeakLeash i ACK Cyfronet AGH. Dlaczego warto zainteresować się tym projektem? Bo Bielik to więcej niż tylko kolejny model – to wynik determinacji jego twórców. W tym artykule przedstawimy wam informacje o Bieliku i odsłonimy przed wami kulisy powstania tego narzędzia. Zapraszamy do lektury!
Charakterystyka Bielika
Bielik, jak już wspomnieliśmy, jest dostępny w wersji bazowej i instruct. Ten model ma 7 miliardów parametrów i jego architektura jest oparta na architekturze modelu Mistral-7B-v0.1. Bielik został wytrenowany na korpusie języka polskiego przygotowanym przez zespół SpeakLeash i w tym celu przetworzono 70 miliardów tokenów. Model wytrenowano za pomocą frameworka ALLaMo, którego autorem jest Krzysztof Ociepa, współzałożyciel Azurro (należy też do zespołu SpeakLeash, gdzie m.in. nadzorował proces trenowania modelu). Do stworzenia Bielika użyto superkomputera Helios z krakowskiego ACK Cyfronet AGH (wykorzystano 256 kart NVidia GH200).

Jeśli chodzi o licencje, to wersja bazowa jest opublikowana na licencji komercyjnej, a wersja instruct – ze względu na niepewną sytuację prawną – na licencji niekomercyjnej.
Każdy może przetestować model w wersji instrukcyjnej dzięki wersji demonstracyjnej na Hugging Face. Dostępne są 2 wersje demo: w pełnej precyzji (16bits) i w ograniczonej precyzji (4bits). W przypadku ograniczonej precyzji należy pamiętać, że model może dawać gorszej jakości odpowiedzi, ale za to jest szybki i potrzebuje mało zasobów do działania. Jeśli chcecie przetestować całkowity potencjał Bielika, polecamy skorzystać z wersji w pełnej precyzji.
Testując Bielika warto pamiętać też o tym, że jest to jego pierwsza wersja i ma 7 miliardów parametrów (dla porównania, GPT-3 miał 175 miliardów parametrów). Model nie ma dostępu do bieżących informacji.
Podczas testowania przydatne jest używanie parametru “temperature”. Ustawiając go na 0.0, użytkownik dostaje jak najbardziej precyzyjne odpowiedzi. Im wyższa wartość tego parametru, tym model jest bardziej kreatywny, ale jednocześnie wzrasta prawdopodobieństwo wystąpienia halucynacji, czyli podawania przez model nieprawdziwych informacji.
W przypadku wersji instruct, dostępne są także skwantyzowane opcje. Użytkownicy mogą skorzystać z formatów GGUF, GPTQ, AWQ, EXL2, HQQ i MLX.
Bielik może być z sukcesem stosowany do pracy nad różnymi zadaniami. Sebastian Kondracki, założyciel SpeakLeash, w wywiadzie dla MamStartup przedstawił kilka przykładów możliwego użycia tego modelu:
“Jego zastosowania to przede wszystkim strukturyzacja dokumentów, ekstrakcja wiedzy, a także Retriever-Augmented Generation (RAG), czyli generowanie tekstu wspomagane wyszukiwaniem informacji. Model ten wykazuje także zdolności do wykrywania emocji w tekstach i ich strukturyzacji.”
Innym ciekawym przykładem podanym w tym wywiadzie, w którym dodatkowo Bielik radzi sobie lepiej niż model GPT-4, jest generowanie tekstów w gwarze śląskiej.
Zachęcamy was do przetestowania Bielika – być może to właśnie wy znajdziecie jakiś ciekawy use case, a dodatkowo możecie wesprzeć twórców, przekazując im swój feedback, co na pewno pozytywnie wpłynie na kolejne wersje tego modelu.
Jaka jest historia powstania Bielika?
Dane techniczne Bielika z pewnością są ciekawe dla osób interesujących się generatywną sztuczną inteligencją czy ogólnie technologią, jednak historia powstania tego modelu jest równie fascynująca. Jak już wspomnieliśmy, Bielik został stworzony przez zespół SpeakLeash we współpracy z Cyfronetem. Polecamy wam przeczytać wspomniany wyżej wywiad z Sebastianem Kondrackim, żeby dowiedzieć się wielu ciekawostek o tym, jak powstawał Bielik. Poniżej opiszemy wam najważniejsze informacje dotyczące tego projektu zawarte właśnie w tym wywiadzie.
SpeakLeash to zespół pasjonatów, którzy swój wolny czas poświęcają pracy nad projektem. Obecnie na Discordzie tej grupy jest około 400 członków. Na początku swojej działalności, ta organizacja postawiła sobie za cel zebranie 1 TB tekstów w języku polskim, które w późniejszym czasie mogłyby być użyte właśnie do wytrenowania modelu językowego. Ten cel SpeakLeash już osiągnął i na chwilę obecną zebrano 1.48 TB danych:
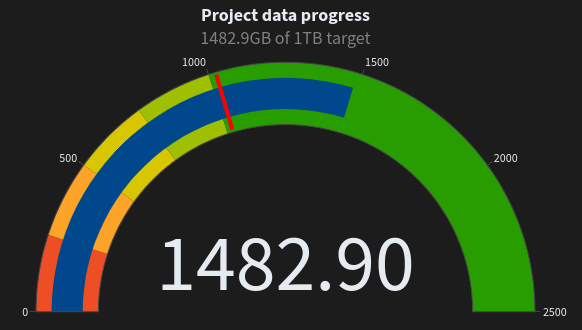
Jak mówi założyciel SpeakLeash, mało kto wierzył, że osiągnięcie tego celu i praca nad projektem są możliwe w przypadku grupy osób, która nie ma sponsorów i żadnej osobowości prawnej. Okazało się jednak inaczej i mało tego, SpeakLeash stworzył swój własny polski model językowy na podstawie zebranego zbioru, a to wszystko stało się w ciągu 1.5 roku. Ciekawostką jest fakt, że Bielik został zbudowany z budżetem wynoszącym około 1-2 tysiąca złotych. Oczywiście stworzenie Bielika jest też nieocenioną zasługą Cyfronetu, który udostępnił swój superkomputer Helios do jego wytrenowania.
Proces tworzenia Bielika był wyzwaniem, ale także źródłem nieustannej motywacji. Zespół SpeakLeash, zróżnicowany pod względem zawodowym i osobistym, zjednoczony był w celu stworzenia czegoś wyjątkowego. Właśnie ta różnorodność sprawiła, że prace nad Bielikiem były inspirujące, nawet w najbardziej monotonnych momentach.
Oczywiście pojawiły się pewne wyzwania w trakcie pracy nad projektem, takie jak opinie sugerujące zbędność polskich modeli językowych oraz regulacje prawne, które mogłyby ograniczyć możliwości tworzenia modeli AI. Jednak zespół pozostał zmotywowany, gotowy kontynuować pracę i udowodnić wartość polskich inicjatyw w dziedzinie sztucznej inteligencji.
Projekt Bielik narodził się z przekonania, że Polska potrzebuje własnych narzędzi w dziedzinie sztucznej inteligencji. Krajowe modele językowe są kluczowe ze względu na kulturowe i językowe niuanse, którymi dysponują. W przeciwieństwie do zagranicznych odpowiedników, Bielik operuje na bazie polskiej rzeczywistości językowej, co sprawia, że jest bardziej dostosowany do lokalnych potrzeb i specyfiki.
Wierząc w potencjał Bielika, Sebastian Kondracki podkreśla, że chociaż pierwsza wersja modelu może jeszcze nie zrewolucjonizować rynku, to już teraz zyskuje uznanie użytkowników. Jego zdolności sprawiają, że stanowi solidne narzędzie, które może być użyte w różnych dziedzinach, od służby zdrowia po sektor publiczny. Ważne jest też to, że projekt jest otwarty, co pozytywnie wpływa na współpracę między różnymi organizacjami – nie konkurują one ze sobą, tylko wymieniają się doświadczeniami.
Podsumowując, Bielik to nie tylko kolejny model językowy. To manifest determinacji, otwartości i współpracy, który może zmienić sposób, w jaki postrzegamy i wykorzystujemy sztuczną inteligencję w Polsce.
Podsumowanie
Zbudowanie i opublikowanie Bielika otwiera nowy rozdział w dziedzinie polskiej generatywnej sztucznej inteligencji. Już niebawem mają zostać opublikowane kolejne modele, chociażby PLLuM. Dzięki bezinteresownemu zaangażowaniu i ciężkiej pracy tak wielu osób Polska może mieć swoje własne duże modele językowe.
Jeszcze raz zachęcamy was do przetestowania Bielika!
