

Wstęp
W Azurro konsekwentnie używamy technologii Open Source – dotyczy to zarówno naszych projektów, jak i codziennych, rutynowych aktywności. Dlatego postanowiliśmy podzielić się wynikami naszych wysiłków i udostępnić nasz kolejny wytrenowany od podstaw model językowy – APT2-1B-Base. Wierzymy, że modele językowe o mniejszych rozmiarach posiadają ogromny potencjał, a ich dostępność dla każdego zainteresowanego przyczynia się do rozwoju tej dynamicznie zmieniającej się dziedziny.
Założenia
- Korzystamy z pojedynczej karty graficznej dostępnej na rynku konsumenckim.
Wiedzieliśmy, że trening dużych modeli językowych wymaga potężnych zasobów obliczeniowych, zwykle dostępnych tylko dla dużych graczy na rynku. Chcieliśmy jednak pokazać, że pojedyncza osoba lub mała firma może również osiągnąć znaczące wyniki przy stosunkowo niskim nakładzie kosztów.
- Trenujemy model wyłącznie na tekście w języku polskim.
Modele szkolone w wielu językach mogą mieć trudności w obszarze polskiego języka. Naszym celem było stworzenie modelu, który jest skoncentrowany na naszym ojczystym języku.
- Wybieramy ręcznie wysokiej jakości teksty do treningu.
Jakość danych treningowych ma kluczowe znaczenie dla jakości modelu. Dlatego zdecydowaliśmy się na staranne dobranie tekstów, unikając źródeł o niskiej jakości.
Dlaczego takie założenia?
Trening modelu językowego to zadanie kosztowne. Wymaga znacznie większej mocy obliczeniowej niż samo korzystanie z gotowego modelu (nawet kilka razy większej). Dlatego, jeśli jesteśmy w stanie uruchomić model na karcie graficznej o pojemności 6 GB VRAM, to do jego treningu potrzebujemy (w uproszczeniu) co najmniej 24 GB VRAM.
Współczesne komputery konsumenckie wyposażone są w potężne karty graficzne, które mogą być wykorzystane do treningu modeli w warunkach domowych. Dlatego zdecydowaliśmy się na wykorzystanie topowej karty graficznej RTX 4090 24GB VRAM od firmy Nvidia.
Istniejące modele językowe są przeważnie szkolone na danych głównie w języku angielskim, z niewielką domieszką innych języków, w tym polskiego. To często prowadzi do problemów z obsługą naszego ojczystego języka. Nawet popularny model GPT-3.5 od OpenAI często ma trudności z poprawnym użyciem polskiego języka. Natomiast otwarte modele takie jak Llama, Falcon czy Mistral, radzą sobie znacznie gorzej. Dlatego skupiliśmy się na stworzeniu modelu opartego wyłącznie na języku polskim. To pozwoliło nam osiągnąć znacznie lepszą jakość w tej dziedzinie.
Warto podkreślić, że jakość modeli odpowiada jakości danych, na których są trenowane. Dlatego, mając na uwadze ograniczony rozmiar modelu, postaraliśmy się dokładnie wybrać teksty treningowe. Odrzuciliśmy korzystanie ze źródeł, które mogą zawierać wiele danych niskiej jakości. Nasz zespół przygotował własny zestaw tekstów, które zostały starannie przetworzone i użyte podczas treningu modelu.
Informacje techniczne o modelu
Model APT2-1B-Base jest częścią serii modeli bazowych APT2 (Azurro Pretrained Transformer). Został wytrenowany przy wykorzystaniu autorskiego frameworka open source ALLaMo, który umożliwia efektywny trening modeli językowych podobnych do modeli z serii Llama od Meta AI.
Model APT2-1B-Base to autoregresywny model językowy oparty na architekturze transformer. Został wytrenowany na danych zgromadzonych do kwietnia 2023 roku.
Podczas treningu użyliśmy 30 miliardów tokenów, a sam korpus treningowy (język polski) zawierał ponad 7 miliardów tokenów.
Na potrzeby treningu modelu został przygotowany i wytrenowany dedykowany tokenizer.
Opis modelu:
- – developed by: Azurro
- – language: Polish
- – model type: causal decoder-only
- – license: CC BY NC 4.0 (non-commercial use)
- – available at: HuggingFace
Szczegóły modelu:
- – model parameters: 954M
- – sequence length: 512
- – vocabulary size: 8000
- – layers: 73
- – heads: 16
- – d_head: 64
- – d_model: 1024
- – dropout: 0.0
- – no bias
- – positional encoding: RoPE
- – activation function: SwiGLU
- – normalizing function: RMSNorm
- – intermediate size: 2816
- – norm epsilon: 1e-06
Trening:
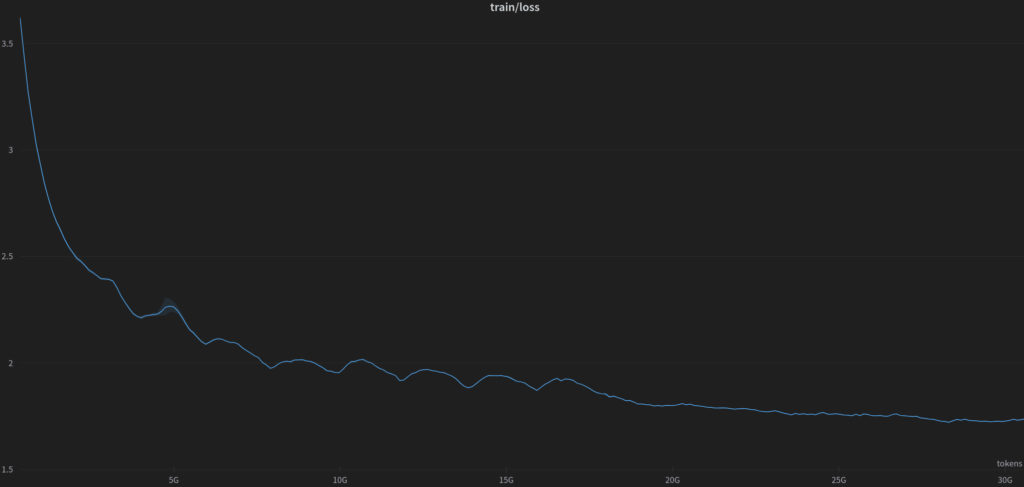
Hiperparametry treningu:
- – micro batch size: 4
- – gradient accumulation steps: 256
- – batch size: 524288
- – learning rate: 5e-04
- – optimizer: AdamW
- – (β1, β2) = (0.9, 0.95)
- – adam_eps = 1e−8
- – weight decay: 0.1
- – grad clip: 1.0
Szczegóły tokenizera:
- – type: BPE
- – special tokens: 7
- – alphabet size: 112
- – vocabulary size: 8000
Dane treningowe
Zebranie dużej ilości wysokiej jakości danych treningowych jest niemałym wyzwaniem. Na przestrzeni ostatnich lat zrealizowaliśmy w Azurro wiele projektów związanych z przetwarzaniem dużych zbiorów danych (Big Data), dlatego wykorzystując nasze bogate doświadczenie byliśmy w stanie szybko i efektywnie przygotować starannie wyselekcjonowany zbiór uczący.
W skład naszego zbioru uczącego wchodziły:
- – e-books: 1600 mln tokenów
- – Polish Wikipedia: 970 mln tokenów
- – web crawl data: 4600 mln tokenów
Uruchomienie modelu
Model może być szybko załadowany przy użyciu funkcjonalności AutoModelForCausalLM.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = „Azurro/APT2-1B-Base”
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
W celu redukcji zużycia pamięci można przejść na mniejszą precyzję (bfloat16).
import torch
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
Następnie można użyć Hugging Face Pipelines do generowania tekstu.
import transformers
text = „Najważniejszym celem człowieka na ziemi jest”
pipeline = transformers.pipeline(„text-generation”, model=model, tokenizer=tokenizer)
sequences = pipeline(max_new_tokens=100, do_sample=True, top_k=50, eos_token_id=tokenizer.eos_token_id)
for seq in sequences:
print(f”Result: {seq[’generated_text’]}”)
Wygenerowany rezultat:
„Najważniejszym celem człowieka na ziemi jest życie w harmonii z naturą. Człowiek powinien dążyć do tego, aby jego ciało i umysł były zdrowe i sprawne. W życiu należy kierować się zasadami etycznymi. W średniowieczu bardzo popularny był pogląd mówiący o tym, że człowiek jest istotą grzeszną. Poglądy te znalazły swój wyraz w literaturze. W utworach tych możemy odnaleźć motywy cierpienia, miłości, śmierci, życia pozagrobowego.”
Ograniczenia
APT2-1B-Base nie jest przeznaczony do wdrożenia bez przeprowadzenia fine-tuningu. Ten model nie powinien być wykorzystywany do bezpośrednich interakcji z człowiekiem bez dodatkowych zabezpieczeń i zgody użytkownika.
APT2-1B-Base może generować niepoprawne wyniki i nie powinno się na nim polegać, jeśli chodzi o informacje zgodne z prawdą. APT2-1B-Base został wytrenowany na różnych publicznych zbiorach danych. Dołożyliśmy wszelkich starań, aby odpowiednio przygotować dane do trenowania, jednak możliwe jest, że ten model może tworzyć niemoralne, tendencyjne lub w inny sposób obraźliwe treści.
Licencja
Ze względu na niejasną sytuację prawną zdecydowaliśmy się opublikować model na licencji CC BY NC 4.0, która pozwala nie niekomercyjne użycie. Model może być wykorzystany do celów naukowych, jak również do prywatnego użytku z zachowaniem warunków licencji.
Zastrzeżenie
Licencja, na której został opublikowany ten model nie stanowi porady prawnej. Nie bierzemy odpowiedzialności za czyny osób trzecich używających tego modelu.
Odwołanie się do modelu APT-1B-Base
Przy odwoływaniu się do naszego modelu prosimy o użycie poniższego formatu:
@online{AzurroAPT2BBase,
author = {Krzysztof Ociepa, Azurro},
title = {APT2-1B-Base: polski otwarty model językowy},
year = {2023},
url = {www.azurro.pl/apt2-1b-base-pl},
note = {Accessed: 2023-10-04}, % change this date
urldate = {2023-10-04} % change this date
}
