

Wstęp
W Azurro konsekwentnie używamy technologii Open Source – dotyczy to zarówno naszych projektów, jak i codziennych, rutynowych aktywności. Dlatego postanowiliśmy podzielić się wynikami naszych wysiłków i udostępnić nasz kolejny wytrenowany od podstaw model językowy – APT2-1B-Base. Wierzymy, że modele językowe o mniejszych rozmiarach posiadają ogromny potencjał, a ich dostępność dla każdego zainteresowanego przyczynia się do rozwoju tej dynamicznie zmieniającej się dziedziny.
Założenia
Trenowanie dużych modeli językowych wymaga ogromnej mocy obliczeniowej i jest zarezerwowane dla dużych graczy na rynku. Ale czy to znaczy, że pojedyncza osoba czy mała firma nie może trenować modeli językowych, które będą w stanie wykonywać określone zadania? Postanowiliśmy odpowiedzieć na to pytanie i wytrenować własny model językowy od podstaw.
Postawiliśmy sobie następujące założenia:
- – używamy 1 konsumenckiej karty graficznej
- – trenujemy tylko na korpusie języka polskiego
- – trenujemy na ręcznie wyselekcjonowanym tekście wysokiej jakości
Dlaczego właśnie takie założenia?
Na wstępie trzeba zaznaczyć, że trening modelu wymaga minimum kilka razy więcej zasobów niż późniejsze jego używanie. W uproszczeniu można przyjąć, że jest to minimum około 3-4 razy więcej. Dlatego jeśli model da się uruchomić na karcie graficznej, która ma 6 GB VRAM, to do wytrenowania tego modelu będziemy potrzebować co najmniej około 24 GB VRAM.
Wiele konsumenckich komputerów wyposażonych jest w dobre karty graficzne, które mogą być wykorzystane do trenowania modelu w domowych warunkach. Dlatego zdecydowaliśmy się wykorzystać topową konsumencką kartę graficzną RTX 4090 24GB VRAM firmy Nvidia.
Wszystkie dostępne obecnie modele językowe zostały wytrenowane na korpusach głównie anglojęzycznych, z niewielką domieszką innych języków, w tym języka polskiego. Skutkiem tego jest nienajlepsze radzenie sobie z naszym ojczystym językiem. Nawet popularne modele GPT od OpenAI czy Bard od Google często mają problem z poprawnymi odmianami czy sformułowaniami. Dlatego zdecydowaliśmy się przygotować model tylko w oparciu o korpus języka polskiego. Dodatkowym argumentem był rozmiar samego modelu – dla mniejszego modelu lepiej skupić się na jednym języku.
Modele są tak dobre, jak dane, na jakich są wytrenowane. Mając na uwadze mały rozmiar modelu, postanowiliśmy nauczyć go starannie wyselekcjonowanym tekstem. Dlatego nie bazowaliśmy na dostępnych korpusach takich jak Common Crawl, które zawierają dużo słabej jakości danych. Dzięki bliskiej współpracy i poradom od zespołu Speakleash, nasz zespół przygotował ponad 285 GB korpusu tekstowego w języku polskim, który został następnie przetworzony i wykorzystany do szkolenia modelu. Dodatkowo, wyjątkową cechą naszego modelu jest to, że został on wytrenowany na największej ilości tekstu spośród wszystkich dostępnych modeli dla języka polskiego.
Model
Model APT3-1B-Base został wytrenowany przy pomocy autorskiego frameworka open source ALLaMo, który pozwala na szybki i efektywny trening modeli językowych podobnych do modeli z serii LLaMA od Meta AI.
Model APT3-1B-Base jest autoregresywnym modelem językowym zbudowanym w oparciu o architekturę transformer. Został wytrenowany na danych zebranych do końca grudnia 2023.
Dostępna jest także wersja instruct tego modelu (APT3-1B-Instruct-v1) na HuggingFace.
Zestaw treningowy (korpus języka polskiego) zawiera ponad 60 miliardów tokenów, wszystkie z nich zostały użyte do treningu na 1 epoce.
Na potrzeby treningu modeli z serii APT3 został przygotowany i wytrenowany dedykowany tokenizer.
Opis modelu:
- – developed by: Azurro
- – language: Polish
- – model type: causal decoder-only
- – license: CC BY NC 4.0 (non-commercial use)
- – available at: HuggingFace
Szczegóły modelu:
| Hyperparameter | Value |
|---|---|
| Model Parameters | 1041M |
| Sequence Length | 2048 |
| Vocabulary Size | 31980 |
| Layers | 18 |
| Heads | 32 |
| d_head | 64 |
| d_model | 1024 |
| Dropout | 0.0 |
| Bias | No |
| Positional Encoding | RoPE |
| Activation Function | SwiGLU |
| Normalizing Function | RMSNorm |
| Intermediate Size | 5504 |
| Norm Epsilon | 1e-06 |
Szczegóły tokenizera:
- – type: BPE
- – special tokens: 8
- – alphabet size: 113
- – vocabulary size: 31980
Trening:
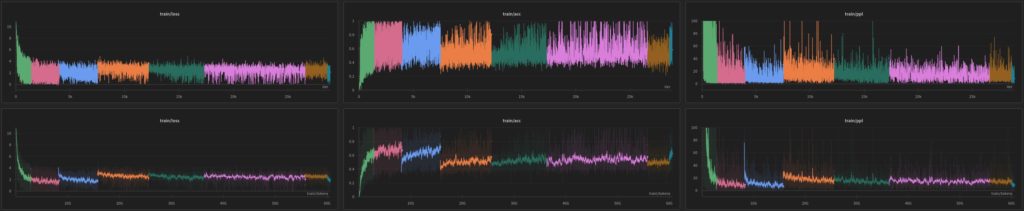

Hiperparametry treningu:
| Hyperparameter | Value |
|---|---|
| Micro Batch Size | 1 |
| Gradient Accumulation Steps | 1024 |
| Batch Size | 2097152 |
| Learning Rate (cosine) | 2e-04 -> 2e-05 |
| Warmup Iterations | 1000 |
| All Iterations | 28900 |
| Optimizer | AdamW |
| β1, β2 | 0.9, 0.95 |
| Adam_eps | 1e−8 |
| Weight Decay | 0.1 |
| Grad Clip | 1.0 |
| Precision | bfloat16 |
Dane treningowe
Zebranie dużej ilości wysokiej jakości danych treningowych jest niemałym wyzwaniem. Na przestrzeni ostatnich lat zrealizowaliśmy w Azurro wiele projektów związanych z przetwarzaniem dużych zbiorów danych (Big Data), dlatego wykorzystując nasze bogate doświadczenie byliśmy w stanie szybko i efektywnie przygotować starannie wyselekcjonowany zbiór uczący.
Nasza ścisła współpraca z zespołem Speakleash zaowocowała stworzeniem ponad 285 GB korpusu tekstu w języku polskim. Proces przygotowania zbioru treningowego obejmował przekształcanie dokumentów poprzez zastosowanie różnych reguł, a następnie wybór dokumentów o odpowiedniej jakości.
W skład naszego zbioru uczącego wchodziły:
- – 150 zestawów danych od Speakleash – 93%
- – inne publicznie dostępne i pozyskane z przeszukiwania internetowego dane – 6%
- – polska Wikipedia – 1%
Uruchomienie modelu
Model może być szybko załadowany przy użyciu funkcjonalności AutoModelForCausalLM:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = „Azurro/APT3-1B-Base”
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
W celu redukcji zużycia pamięci można przejść na mniejszą precyzję (bfloat16):
import torch
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
Następnie można użyć Hugging Face Pipelines do generowania tekstu:
import transformers
text = „Najważniejszym celem człowieka na ziemi jest”
pipeline = transformers.pipeline(„text-generation”, model=model, tokenizer=tokenizer)
sequences = pipeline(max_new_tokens=100, do_sample=True, top_k=50, eos_token_id=tokenizer.eos_token_id, text_inputs=text)
for seq in sequences:
print(f”Result: {seq[’generated_text’]}”)
Wygenerowany tekst:
„Najważniejszym celem człowieka na ziemi jest życie w pokoju, harmonii i miłości. Dla każdego z nas bardzo ważne jest, aby otaczać się kochanymi osobami.”
Ograniczenia
APT3-1B-Base nie jest przeznaczony do wdrożenia bez przeprowadzenia fine-tuningu. Ten model nie powinien być wykorzystywany do bezpośrednich interakcji z człowiekiem bez dodatkowych zabezpieczeń i zgody użytkownika.
APT3-1B-Base może generować niepoprawne wyniki i nie powinno się na nim polegać, jeśli chodzi o informacje zgodne z prawdą. APT3-1B-Base został wytrenowany na różnych publicznych zbiorach danych. Dołożyliśmy wszelkich starań, aby odpowiednio przygotować dane do trenowania, jednak możliwe jest, że ten model może tworzyć niemoralne, tendencyjne lub w inny sposób obraźliwe treści.
Licencja
Ze względu na niejasną sytuację prawną zdecydowaliśmy się opublikować model na licencji CC BY NC 4.0, która pozwala nie niekomercyjne użycie. Model może być wykorzystany do celów naukowych, jak również do prywatnego użytku z zachowaniem warunków licencji.
Zastrzeżenie
Licencja, na której został opublikowany ten model nie stanowi porady prawnej. Nie bierzemy odpowiedzialności za czyny osób trzecich używających tego modelu.
Odwołanie się do modelu APT3-1B-Base
Przy odwoływaniu się do naszego modelu prosimy o użycie poniższego formatu:
@online{AzurroAPT3Base1B,
author = {Krzysztof Ociepa, Azurro},
title = {APT3-1B-Base: polski otwarty model językowy},
year = {2024},
url = {www.azurro.pl/apt3-1b-base-pl},
note = {Accessed: 2024-01-04}, % change this date
urldate = {2024-01-04} % change this date
}
Specjalne podziękowania
Chcielibyśmy szczególnie podziękować zespołowi Speakleash za zebranie i udostępnienie tekstów w języku polskim, a także za wsparcie, na które zawsze mogliśmy liczyć podczas przygotowywania zestawu treningowego dla naszego modelu. Bez Was on by nie powstał. Dziękujemy!
Zespół Azurro
Możesz dowiedzieć się więcej o naszym zespole na naszej stronie głównej.
Skontaktuj się z nami
Jeśli masz jakiekolwiek pytania lub sugestie, wyślij nam e-mail na [email protected].
