
Wszyscy możemy się zgodzić, że rok 2023 był przełomowy w dziedzinie dużych modeli językowych. Pod koniec 2022 roku OpenAI opublikowało ChatGPT, a po tym wydarzeniu, w minionym roku, wiele innych firm i organizacji zaczęło udostępniać swoje modele i to w dość zawrotnym tempie. Byliśmy świadkami powstawania masy nowych narzędzi z tygodnia na tydzień – na Hugging Face dostępnych jest już ponad 556 tysięcy modeli (jest to stan na marzec 2024; dla porównania, w styczniu 2024 było ich około 100 tysięcy mniej).
Na naszym blogu mogliście już przeczytać artykuł o przyszłości dużych modeli językowych, jednak nie musicie się obawiać, że teraz powtórzymy informacje tam zawarte. Ta dziedzina rozwija się tak dynamicznie, że warto być na bieżąco, dlatego chcemy podać wam najświeższe informacje o konkretnych rozwiązaniach, o których zaczęło się robić głośno pod koniec 2023 roku i na początku 2024 roku. Zapraszamy do lektury!
GPTs – kolejna nowość od OpenAI
Pod koniec roku (6 listopada 2023) OpenAI znów wprowadziło coś nowego – mowa o GPTs, czyli o wersjach ChatGPT dostosowanych do potrzeb użytkowników przez nich samych. Oznacza to, że każdy może stworzyć własny ChatGPT, który będzie wykonywał jakiś określony typ zadań – i nie trzeba wcale umieć programować, bo wystarczy podać prompty i ewentualnie własne dane. Użytkownicy mogą tworzyć modele tylko dla siebie, na użytek jedynie swojej firmy, organizacji lub innego rodzaju grupy lub mogą się dzielić nimi ze społecznością. Można stworzyć narzędzie do jakiegokolwiek celu, np. do nauki słów w jakimś obcym języku, do stworzenia swojego osobistego wirtualnego asystenta czy do projektowania plakatów dla dzieci.
OpenAI otworzyło także GPT Store, czyli miejsce, gdzie możemy przeszukiwać GPTs stworzone i udostępnione przez zweryfikowanych użytkowników. Co ciekawe, OpenAI twierdzi, że użytkownicy będą mogli zarabiać na swoich GPTs.
Niewątpliwie jest to ciekawe rozwiązanie, które będzie dalej rozwijane w 2024 roku i zapewne będzie miało wpływ na to, co będzie się dalej działo w obszarze generatywnej sztucznej inteligencji.
Mistral AI
Mistral AI to stosunkowo młody, francuski start-up założony przez Arthura Menscha (wcześniej pracował dla Google DeepMind), Guillaume’a Lample’a i Timothée’a Lacroix (pracowali w Meta Platforms). Ta firma istnieje od 28 kwietnia 2023 i bardzo szybko pozyskała fundusze na rozwój swojej działalności – w październiku 2023 uzyskała już łącznie 385 milionów euro, a jej wartość w grudniu wyceniono na ponad 2 miliardy dolarów. Co ciekawe, w Mistral AI pracuje nieco ponad 20 osób, czyli znacznie mniej, niż w innych powszechnie znanych firmach zajmujących się dużymi modelami językowymi (np. OpenAI w styczniu 2023 zatrudniało ponad 770 osób).
Ten start-up do tej pory stworzył kilka różnych modeli językowych, które szybko stały się popularne w świecie generatywnej sztucznej inteligencji. Mistral AI początkowo tworzyła modele typu open source – Mistral 7B i Mixtral 8x7B.
Mistral 7B to pierwszy model tej firmy. Został opublikowany we wrześniu 2023. Ma ponad 7 miliardów parametrów i według twórców osiąga lepsze wyniki niż LLaMA 2 13B i jest na równi z LLaMA 34B.
Kolejny model, Mixtral 8x7B, został opublikowany w grudniu. Ten model ma odmienną architekturę – sparse mixture of experts architecture, co oznacza, że jest modelem ekspertowym (pisaliśmy już o modelach ekspertowych w naszym artykule na temat przyszłości LLMs). Mixtral 8x7B ma 8 podzbiorów, tzw. ekspertów. Łącznie dostępnych jest 46.7 miliardów parametrów, ale każdy token może użyć jedynie 12.9 miliardów parametrów. Oznacza to, że przy ponad 46 miliardach dostępnych parametrów model potrzebuje tyle mocy obliczeniowej i generuje koszty takie, jak model o wielkości 12.9 miliardów parametrów. Według Mistral AI, Mixtral 8x7B w większości benchmarków osiąga lepsze wyniki niż LLaMA 70B i GPT-3.5. Twórcy utrzymują też, że Mixtral 8x7B jest bardzo dobry w pisaniu kodu.
Oprócz modeli typu open-source, Mistral AI stworzyło także takie, które od 26 lutego 2024 są dostępne przez płatne API: Mistral Small, Mistral Medium i Mistral Large. Mistral AI nie opublikowało informacji na temat tego, ile te modele mają parametrów. Mistral Large to flagowy produkt tej francuskiej firmy. Osiąga bardzo wysokie wyniki w popularnych benchmarkach, co czyni go trzecim najlepszym modelem dostępnym przez API na świecie (zaraz po GPT-4 i Claude 3 Opus, który nie został uwzględniony na poniższym diagramie, ponieważ nie był w tym czasie jeszcze opublikowany – opisujemy go w kolejnej sekcji tego artykułu):
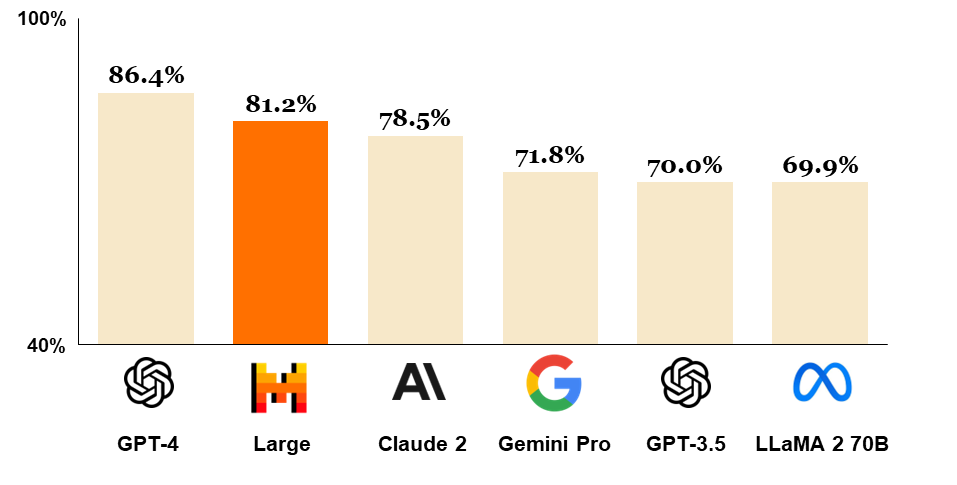
Dzięki niedawno nawiązanej współpracy z Microsoft, wszystkie modele Mistral AI są dostępne na platformie Azure. Oprócz tego, można uzyskać do nich dostęp przez własną platformę tej francuskiej firmy (Le Plateforme).
Mistral AI opracowało także asystenta konwersacyjnego – Le Chat – który obecnie jest w fazie demonstracyjnej. Za pomocą tego narzędzia twórcy chcą pokazać, do czego można wykorzystać ich modele. Le Chat używa Mistral Small, Mistral Large i prototypowego modelu Mistral Next.
Modele Claude
Jak widać na powyższym diagramie, model Claude 2 został oceniony jako 3. najlepszy model na świecie dostępny za pośrednictwem API (4., jeśli weźmiemy pod uwagę także Claude 3 Opus). Został stworzony przez amerykański start-up Anthropic, którego założyciele to byli pracownicy OpenAI. Najnowsza wersja tego modelu, czyli Claude 2.1, została opublikowana w listopadzie 2023. Model praktycznie od razu został uznany jako taki, który może dorównywać GPT-4.
Claude 2 wyróżniło okno kontekstowe, czyli to, ile tokenów można podać jednocześnie – w tym przypadku jest to 100 tysięcy tokenów, co przekłada się na około 75 tysięcy słów. Dla porównania, maksymalna liczba tokenów w przypadku GPT-4 to 8192, a w przypadku Mistral Large 32 tysiące.
4 marca firma Anthropic opublikowała kolejne modele – Claude 3. Grupa Claude 3 zawiera 3 rozmiary modelu: Haiku, Sonnet i Opus: Haiku jest najtańszy, Sonnet jest droższy, a Opus najdroższy, ale też najbardziej zaawansowany i uzyskuje najlepsze wyniki. Anthropic stworzyło te 3 opcje, żeby użytkownicy mogli wybrać taki model, który najlepiej odpowiada ich oczekiwaniom co do ceny i zastosowania. Każdy z tych trzech modeli może obsługiwać prompty, które składają się z 200 tysięcy tokenów – co więcej, firma Anthropic twierdzi, że te modele mogą przyjąć nawet milion tokenów jednocześnie, ale taka opcja będzie dostępna jedynie dla użytkowników, którzy potrzebują aż takiego okna kontekstowego.
Wersja Opus osiąga niesamowite wyniki w testach, co widać w tabeli opublikowanej przez Anthropic:
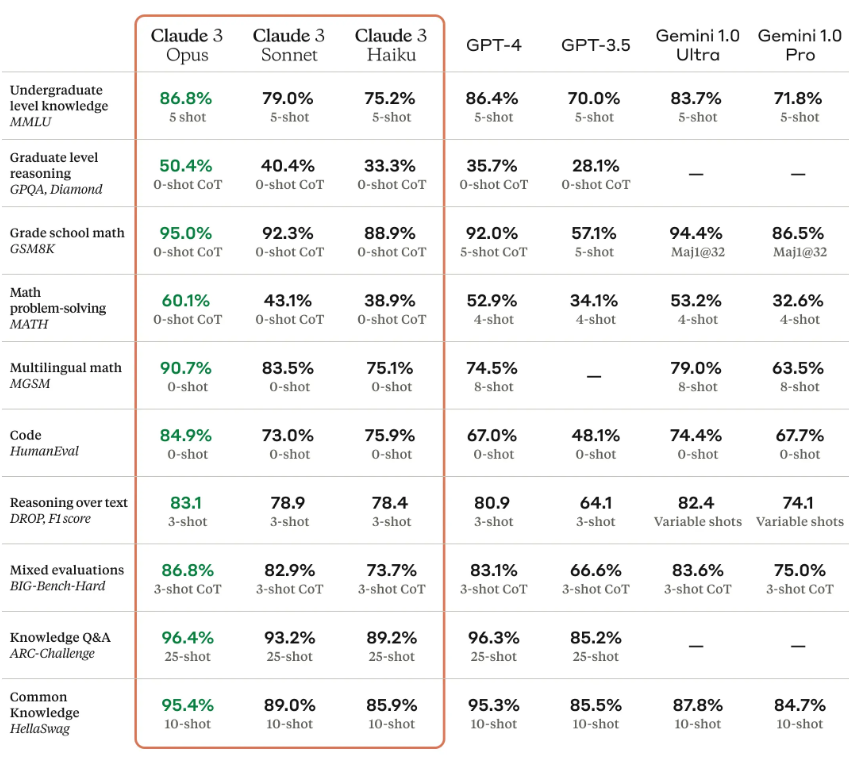
Opcja Opus osiągnęła najwyższe wyniki w każdym benchmarku, przebijając GPT-4 i Gemini 1.0 Ultra – nic więc dziwnego, że jest o nim w ostatnim czasie tak głośno.
Anthropic to firma, która w swojej działalności kładzie nacisk nie tylko na wyniki, ale też na bezpieczne i etyczne wykorzystanie dużych modeli językowych. Ten start-up działa zgodnie z “Constitutional AI” – to oznacza, że opracowuje zasady opisujące pożądane zachowanie sztucznej inteligencji. Następnie te zasady są wykorzystywane do szkolenia modeli, żeby nie generowały szkodliwych treści. Według pracowników Anthropic jest to obszar, który jest stale rozwijającą się, odrębną dziedziną nauki.
Gemini
W ostatnim czasie zaszło też trochę zmian w modelach językowych Google DeepMind. Bard (oparty o model PaLM 2) został zastąpiony przez Gemini 1.0 Pro. Sama zmiana w nazwie (czyli zastąpienie domeny Barda przez Gemini, żeby ujednolicić nazewnictwo modeli językowych Google) weszła w życie w lutym 2024 roku, jednak już od grudnia Bard działał właśnie na modelu Gemini 1.0 Pro. Korzystanie z tego modelu jest bezpłatne.
Model Gemini 1.0 Pro jest mniejszy od PaLM 2 – ma 137 miliardów parametrów (PaLM 2 ma 540 miliardów). Według twórców, Gemini 1.0 Pro jest lepszy w kreatywności i zrozumieniu języka naturalnego. Z racji tego, że jest mniejszym modelem, jest szybszy i bardziej wydajny.
8 lutego 2024 roku Google udostępniło też model Gemini 1.0 Ultra (Gemini Advanced). Korzystanie z tego modelu jest płatne. Ten model wypadł lepiej w 6 z 8 benchmarków niż GPT-4. Co ciekawe, jest to pierwszy model, który osiągnął lepsze wyniki niż ludzie specjalizujący się w różnych dziedzinach (np. w prawie) w benchmarku MMLU, który ocenia wydajność modeli w rozumieniu języka naturalnego w wielu zadaniach jednocześnie. Zarówno Gemini 1.0 Pro jak i Gemini 1.0 Ultra mają okno kontekstowe mieszczące 32 tysiące tokenów.
Te 2 modele to nie wszystkie nowości od Google – zaledwie tydzień po udostępnieniu Gemini 1.0 Ultra, Google ogłosiło, że programiści i klienci korporacyjni mogą zacząć testować Gemini 1.5 Pro. Jest to model typu MoE, czyli model ekspertowy, co znacząco przyspiesza przetwarzanie danych i zmniejsza moc obliczeniową potrzebną do wykonania danego zadania. Według Google, ten model radzi sobie z wykonywaniem poleceń porównywalnie do modelu Gemini 1.0 Ultra, ale jest szybszy i wydajniejszy. Domyślnie w jednym poleceniu można podać 128 tysięcy tokenów, ale ograniczona grupa testerów będzie mogła podawać do miliona tokenów. Ciekawostką jest fakt, że w wewnętrznych testach specjalistom z Google udało się przetworzyć prompt składający się z 10 milionów tokenów.
Oprócz rodziny Gemini, 21 lutego 2024 roku opublikowano też modele Gemma. Jest to rodzina modeli typu open-source, które zostały stworzone na podstawie tych samych danych i technologii, które zostały użyte do stworzenia Gemini. Dostępne są 2 wersje: Gemma 2B i 7B (obie w wariantach pre-trained i instruct). Według twórców, modele Gemma osiągają najlepsze wyniki wśród modeli o podobnych rozmiarach (np. Llama 2).
Jak widać, w ciągu ostatnich kilku miesięcy w Google wiele się działo w dziedzinie dużych modeli językowych, a twórcy dostarczają nam coraz to więcej nowości i to w zawrotnym tempie.
SLMs, czyli Small Language Models
Już od pewnego czasu można było usłyszeć, że modele językowe będą poddane miniaturyzacji. To już się dzieje, ponieważ zaczęły powstawać Small Language Models (SLMs) i według wielu opinii będą one mocno rozwijane w 2024 roku.
SLMs mają zazwyczaj mniej parametrów niż LLMs, co oznacza, że wymagają mniej danych do trenowania i potrzebują mniej mocy obliczeniowej, lecz mimo tego mogą dorównywać swoimi wynikami dużym modelom językowym.
Przykładem takiego modelu jest DistilBERT. Został on wytrenowany na podstawie modelu BERT base. DistilBERT ma o 40% mniej parametrów niż Bert Base, działa o 60% szybciej, jednocześnie zachowując ponad 95% wydajności.
SLMs są idealne do wdrożeń na urządzeniach takich jak np. smartfony, gdzie kluczowe znaczenie ma efektywność wykorzystania zasobów. Takie modele mają ogromny potencjał wykorzystania również przez przedsiębiorstwa ze względu na to, że są bardziej ekonomiczne, właśnie dzięki mniejszym wymaganiom sprzętowym. Uważa się też, że ze względu na mniejszy rozmiar te modele są bardziej transparentne (łatwiej jest zrozumieć i sprawdzić, w jaki sposób dochodzą do swoich wniosków) i bezpieczniejsze. Zwykle dane do trenowania SLMs są dokładniej weryfikowane, ponieważ te modele często są stosowane w bardziej wyspecjalizowanych przypadkach niż duże modele językowe (np. w danym języku lub w jednej branży lub firmie). Oznacza to, że są mniej podatne na przejawianie uprzedzeń i bardziej wiarygodne.
Zastosowanie SLMs w konkretnych zadaniach jest podobne, co zastosowanie LLMs. Mogą być używane do automatyzacji zadań związanych z językiem naturalnym, takich jak tłumaczenie, pisanie kreatywnych treści czy tworzenie podsumowań, interakcji z użytkownikami (chatboty, asystenci głosowi) czy do klasyfikacji tekstów, rozpoznawania obrazów i rozpoznawania mowy.
Małe modele językowe stały się coraz częściej poruszanym tematem w świecie generatywnej sztucznej inteligencji. Możemy spodziewać się, że w najbliższym czasie jeszcze nie raz o nich usłyszymy.
Podsumowanie
Ostatnie kilka miesięcy obfitowało w szereg fascynujących wydarzeń w dziedzinie dużych modeli językowych. Prezentowane w niniejszym artykule nowości stanowią jedynie wycinek tego dynamicznie rozwijającego się obszaru. Pozostaje nam z zaciekawieniem obserwować, jakie innowacje przyniesie dalszy ciąg roku i jakie niespodzianki szykują dla nas twórcy LLMs.
