
Background
The percentage contribution of TV broadcasts with subtitles increases every year, and the demand for software transcribing speech to text is high because of the European Union, the U.S. and local regulations regarding the accessibility of digital products and services for people with hearing impairment. The availability of speech-to-text software provided by industry-leading companies (for example, by Microsoft, Google, Amazon), as well as by smaller companies specializing in this particular field is various for different languages. Polish is used by over 40 million people, but it is not as popular as English, Spanish, Mandarin Chinese or other languages. Therefore there are fewer functionalities of speech to text cognitive services used for Polish and other languages of the Central Europe countries, and this software does not provide punctuation marks, diarization (speaker recognition) or capitalization of names, surnames and proper names in live mode. Our purpose is to build a system improving the quality of transcription provided by the already existing speech to text services. In the future, we want to combine transcription and other features in real-time mode.
Our clients
Our customers are leading Polish media groups that are obliged to add subtitles to their materials, but there are also companies working with the media industry, such as content producers and media houses. We have identified two important use cases: generation of subtitles in batch and live modes and indexing the archives with our tool. Additionally, our clients want the subtitles in live mode to be generated automatically or only under an editor’s supervision who can make minor improvements quickly.
System overview
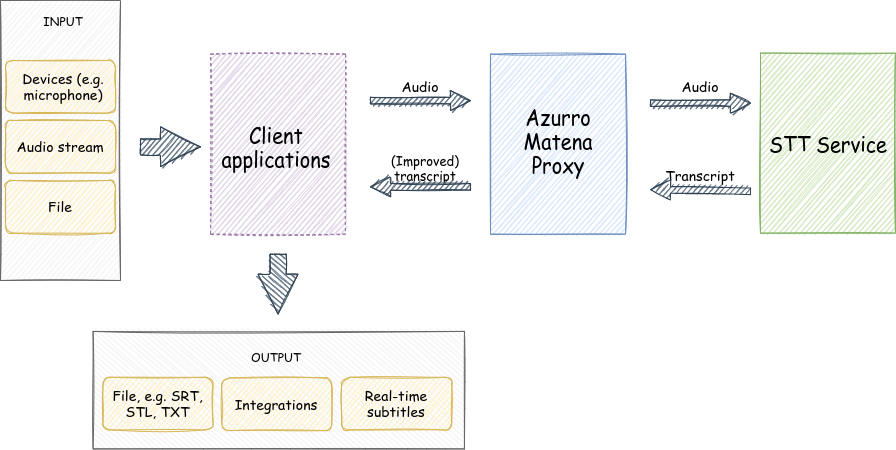
Client applications include software used by our customers, for example:
- – subtitle editing and transmitting tools, e.g. FAB Subtitler, Subtitle Next
- – Voice Bots
- – Azurro Demo Application (application presenting the possibilities of various Speech to Text services in real-time and batch modes)
Azurro Matena Proxy consists of different components, including:
- – proxy (transmitting original transcript from Microsoft Speech to Text service)
- – transcript processing and transformations module
- – logging module (saving messages sent by the client applications and Microsoft STT for analyzing potential issues)
STT (Speech To Text) Service includes:
- – Microsoft Speech To Text using standard language model
- – Custom Speech (STT service with trained language model in dedicated endpoint)
- – there is also a possibility to use speech recognition services provided by other companies
Challenges and our solutions
Live and batch mode of transcription
We needed to implement two modes of speech-to-text transcription: batch mode and live mode. The materials to be transcribed can be live or pre-recorded.
The live mode includes instant transcription, using audio from microphone, line input or file. When run in this mode, the application gets streams of data and transcribes them simultaneously.
The batch mode uses files with recordings prepared before transcription, and the transcription is not made instantly, but after downloading the whole file. The result is provided more quickly than the duration of the original material (it can take as little as 20% of the original material duration).
Testing the accuracy of speech-to-text services
One of the milestones within this project was to test different local and global providers of transcription services for media to check which is the best for specific purposes of our clients.
So far, after testing platforms providing speech-to-text services for the PoC purposes, one of our clients has decided that Microsoft Azure Cognitive Services – Speech to Text (STT) should be used for building the application. However, we have not concluded that the other platforms will not be used in the future – the system architecture is designed in such a way that other transcription solutions can be easily integrated in case other clients would like to use them.
Microsoft Azure Cognitive Services – Speech to Text (STT) has numerous advantages convincing the users to select it for transcription:
- – STT meets the requirements connected with the quality of the batch and live modes of transcription for the Polish language (so far, our clients in this project have been Polish companies);
- – STT is a part of Microsoft Azure Services, and other system components can be also implemented there. For example, our tool can be integrated with Bot Framework or Translator;
- – STT is a cloud service – it is the most popular way of implementation, but there is an option to install STT in dedicated on-premises container;
- – STT is updated frequently and the user is able to see the difference in its quality after it is updated;
- – the cost of using Microsoft services is low – it is about $1-$1.4 per hour of audio material;
- – identifying the speaker is possible in the batch mode. This feature has been also tested with several different speakers in the same recording;
- – there is a possibility to create a custom STT that can be trained with user’s materials. Microsoft’s STT advantage is also the fact that it can be trained with a higher number of words in comparison to the other platforms.
The last advantage on the list (training custom model) is another challenge – it is described in the next chapter.
Training Microsoft custom STT
Another challenge is connected with training the custom STT. Training it means extending the vocabulary used by the basic version of the service and Microsoft Azure Speech Studio is used for this purpose.
We need to prepare the materials used for training. The custom model can be trained with the use of additional texts or sound and corresponding text (although the second option is not provided by Microsoft for less popular languages). Preparing these materials requires a lot of work. When training the model, its vocabulary is also extended with specialized terms. For example, in the case of medical companies, the vocabulary can be extended with medical jargon.
Moreover, when training the model, one needs to take particular care not to overtrain it, because it has an impact on the accuracy of transcription.
Another task connected with training a new custom model is to test its accuracy. Speech Studio (it is also a part of Microsoft Azure Cognitive Services) is used for this purpose. Thanks to this tool, it is possible to prepare materials for training the models and also to test and compare the speech recognition process of several different custom models with the use of human-labeled transcriptions.
We have noticed that when using such system, it is often necessary to update the custom language model used by STT with individual words or phrases coming from current observations. Therefore the end users need a simple and convenient tool for updating the transcription on a daily basis. For this purpose, we have prepared an application called Matena TrainTheModel. It uses Speech Studio API. It allows us to temporarily train the language model with a small set of phrases. This application also collects information about such training datasets – it is useful for preparing a subsequent version of the target model.
Improving the accuracy of the model
Microsoft’s custom STT model has numerous benefits, but there is still a need to improve its accuracy, for example, with the use of various text transformations in the live mode. This was the key argument to build an additional software component – Matena Proxy.
Text transformation is a major challenge, especially in the case of live transcription – this process cannot delay the subtitles, so it also needs to be live. For example, MS custom STT does not recognize the word “covid” in Polish. When the model is trained with the word “kowid”, as it is pronounced in Polish, it then recognizes this world accurately. Then “kowid” is changed to “covid” and the text is correct – such change is an example of a transformation. Transformations can also include capitalization of names, surnames and proper names, and more complex modifications such as improving punctuation, reducing text and combining data from multiple data sources. The above transformations are just some examples, and Matena Proxy is created in such a way that it is easy to implement any other modifications and extensions that the clients want.
Additional benefits of Matena Proxy are flexible integration (for example, with Subtitle Next, FAB Subtitler or any other application used for subtitle editing and transmitting) and the possibility to monitor the transcription process.
Therefore building the system that uses transcription service is not only deciding about which speech to text provider should be used, but also improving the details that have an impact on the accuracy. We integrate knowledge of linguists specializing in Polish, customers experience and feedback to find new transformations and continuously improve the quality of transcription in the Polish language.
User Interface
Azurro Matena, as a set of various functionalities (including Azurro Matena Proxy and TrainTheModel) is available through a web interface. It allows us to authorize users and there is a special admin panel used for managing the users, configuration and tasks, as well as for collecting data and statistics.
Outcome
The project is still developed, and we have multiple ideas for facing future challenges. We are also in the process of deploying software components resulting from this project into our clients’ production systems. Our experience allows us to use the STT technologies and solutions researched in this project and adjust them to our clients needs.
Industry
Media industry
Keywords
Speech-to-text, STT, Speech Recognition, Machine Learning
Technologies
Microsoft Azure Cognitive Services, Microsoft Speech to Text, Microsoft Custom Speech, Microsoft Azure Cloud
