
Background
For our client from the medical industry, we developed a system for monitoring on a daily basis the news on the Internet about specific doctors. We built the system from scratch and we are responsible for all its components.
What the client had
The client was systematically providing us with input csv files containing keywords for search, URLs to be used for monitoring and downloading the data (including Bing news search) and a database containing the list of doctors to be monitored. We needed to use these sources to create the system.
System overview
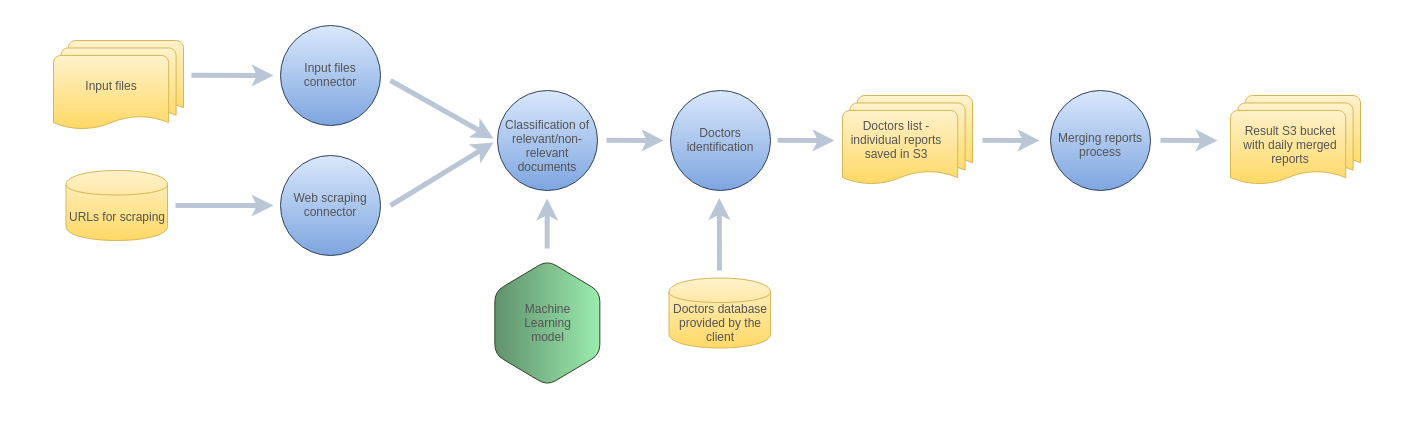
Challenges and our solutions
Data ingestion
As described above, the client provided us with input csv files with the keywords and URLs for scraping, and this input needed to be processed separately by two different components. The system was monitoring the doctors continuously. An important feature of the system is that the client could update or change the csv files with the keywords, URLs and the database with the doctors whenever he wanted to.
Finding relevant documents using Machine Learning
The system was finding different types of documents. Sometimes the documents were non-relevant – it means that they were not about the doctors that the client was interested in. We needed to implement a logic for classifying relevant and non-relevant documents. For this purpose, we trained a Machine Learning model in a supervised manner (we used Support Vector Machine model). This model was trained on data annotated by the client as relevant and non-relevant. We also used TFIDF statistic (among others) for building features. We used a training script allowing us to manipulate the parameters of the SVM algorithm. It was also possible to change the number of TFIDF features calculated for the documents. Thanks to the use of the techniques described above, we trained the model and its accuracy was really high – 99%. The model was used for filtering out non-relevant documents in live production system.
Identifying the names of the doctors
The next step was identifying the doctors in the texts of relevant documents. We used Named-Entity Recognition for this purpose. However, this technique finds proper nouns, and we needed to classify the names of the doctors among them.
For finding the doctors, we created and used 4 lists of keywords and phrases allowing to:
- – identify doctors
- – disqualify a given person from being a doctor (e.g. “a policeman”)
- – determine the distances of the keywords or phrases from names (this is an additional list disqualifying a given person from being a doctor)
- – determine proper nouns other than names (e.g. product names)
After using the above lists to identify the names, we used a scoring mechanism to determine the final list of doctors’ names we identified with the lists above.
The final list of names was compared with the database of the doctors provided by the client. If a name occurred in the list and in the database, it was marked as interesting and it was included in a report with the results.
Reporting the results
The client did not need a UI for presenting the results. Instead, when new input data appeared and when it was processed, an individual report was saved in Amazon S3. The system was running continuously and there was a process triggered once a day that merged these individual reports. As a result, the client was getting daily reports in csv format.
Infrastructure and operations
All components of the system were hosted on Amazon (ECS, S3, RDS, ECR). The components of the system were containerized with the use of Docker and microservices architecture was used for building the system.
Outcome
As a result of our work, the client was provided with a system meeting all his requirements. The client gets daily reports containing articles about the types of doctors that he is interested in. Thanks to this project, the client wanted to cooperate with us again on new challenges.
Industry
Health care
Keywords
Back-end development, Machine Learning
Technologies
Amazon ECS, Amazon ECR, Amazon S3, Python
