
Background
We have been in charge of developing and maintaining a system for our client from the United States specializing in patent prosecution. The system processes the U.S. Patent Trial and Appeal Board decisions relating to patents on a daily basis – it is meant for users who want to become well-informed patent prosecutors or to stay up-to-date with patent appeal trends.
What the client had
When the client contacted us, the system already existed. However, it needed to be updated – it was necessary to improve its performance, develop new functionalities for analytical purposes (including Machine Learning module) and refresh the look of the web application.
System overview
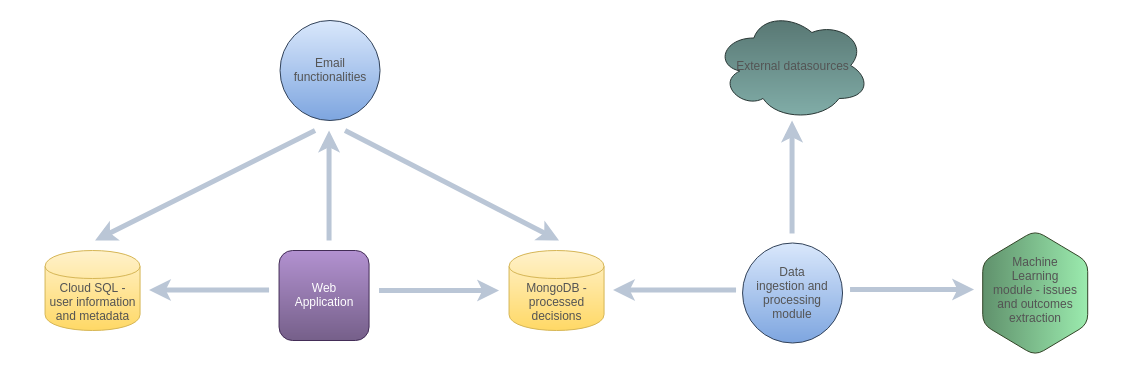
Challenges and our solutions
Data ingestion
The first challenge was to manage data ingestion. We created a special component dealing with downloading and processing the decisions. Patent Examination Data System (PEDS) database is used for getting the documents on a regular basis – the data in the system needs to be up-to-date. Additionally, we download the examiners data from BigQuery, and there was a problem with merging the records from these two datasets. This module downloads the decisions, extracts necessary fields and provides the Machine Learning module with the documents in such a way so that the issues (issues are the basis for making the decision) and outcomes (they are the results of the decision) of the decisions can be retrieved.
Storing and processing the data
The next challenge in this project was connected with storing and processing the data. On one hand, the data needs to be downloaded and processed on a daily basis, but for other component of the system (Office Action Answers), gigabytes of data need to be downloaded and processed once per week – this is required so that it is easy to cache results for user queries. As a solution, we use MongoDB to store the data, and different processing flows (processing on a daily basis and processing the data for Office Action Answers) store the data in different collections.
Machine Learning module
Machine Learning module is used to extract issues and outcomes from the extensive texts of the decisions. The nature of these texts is that they have similar structures, but the issues and outcomes occur in different places of the documents, and the sentences in which they occur are not based on any regular pattern. Additionally, the combinations of issues and outcomes in one document can be really complicated. We used Natural Language Processing techniques to get features that could be used to train a Machine Learning model. This model was trained in a supervised manner based on data annotated by the client. Scikit and Spacy library was used in the case of this model. Developing and improving this module required a lot of work and tests.
Web application
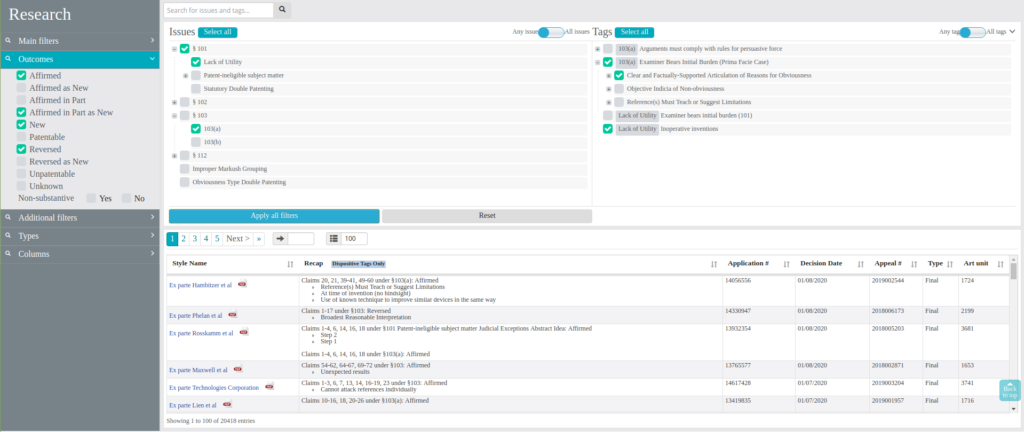
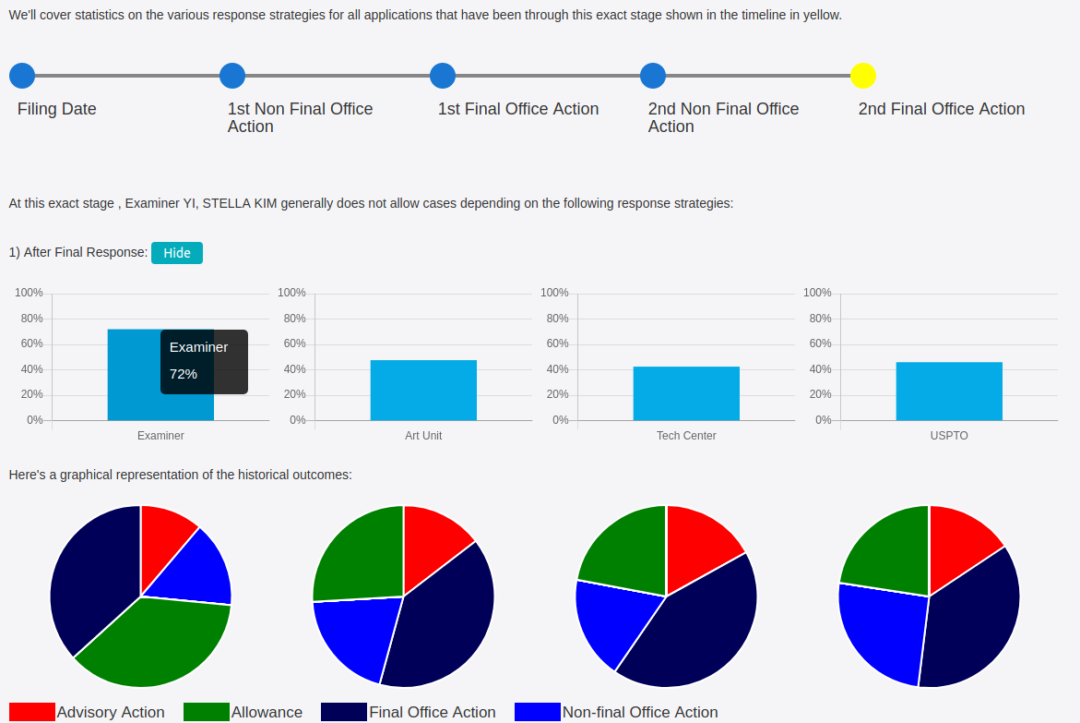
The next challenge was to refresh and expand the web application (written in Django). We needed to redesign the application and create the front-end part so that the client could get numerous custom filters and functionalities allowing the users to do complex research on the data. Web application is also connected with the data prepared on the back-end part by the other components, and we are responsible for the whole pipeline. We also added billing functionality allowing the user to buy a plan with access to specific components of the system.


Email notifications
The client wanted to develop a functionality sending emails to the users with information about new decisions. These emails are customizable – for example, the users can select only specific issues that they are interested in. These emails include the details of these decisions. The emails can be sent on a daily, weekly, biweekly and monthly basis, and there are also custom emails, where the users select the time range that they are interested in.
API
The client also needed an API to allow external access to data for specific users. For this purpose, we created REST endpoints in Django. The users can use these endpoints to make queries and retrieve results in json format. Less technical users can use Swagger to see the results returned by filters (these are the same as the filters available in web application). REST endpoints are created in such a way that they can be used by external users and by internal components of the system.
Infrastructure
The whole system is hosted on Google Cloud Platform. Google Compute Engine and Cloud SQL are used. We decided to use two separate databases – MongoDB is used to store the documents processed by the system, and Cloud SQL is used to store information from user management part and metadata. The system is containerized and every major component runs in a separate Docker container.
Outcome
We designed and developed all functionalities that the client wanted to have. The requests of our client resulted in a long-term cooperation.
Industry
Law
Keywords
Back-end development, Front-end development, Natural Language Processing, Machine Learning
Technologies
Google Cloud Platform, MongoDB, Cloud SQL, Django, Python
